SZARP, since the very beginning (if we exclude short period of SZARP infancy, when it was running on multiple computers under DOS operating system) possesses architecture which is very UNIXy in its spirit. SZARP basically is a collection of processes/applications, where each of the processes is tasked with performing (mostly) one job – and (obviously) performing it well :).
In typical SZARP deployment we have one process that collects values of all parameters, another process that grabs those values and shovels them off into persistent storage, bunch of processes, so called demons, that (typically) communicate with physical devices (usually one process per device), yet another process that make parameters’ values available over HTTP protocol and so on…
All those processes employ the old school UNIX IPC (SYS V) mechanisms to communicate. The parameters’ values are stored in shared memory regions that are accessed using readers-writers locking scheme. Data sent to devices is being passed via queues (again – SYS V IPC primitive).
Here’s an artist’s impression of some of the components comprising SZARP system and the way they are interconnected:
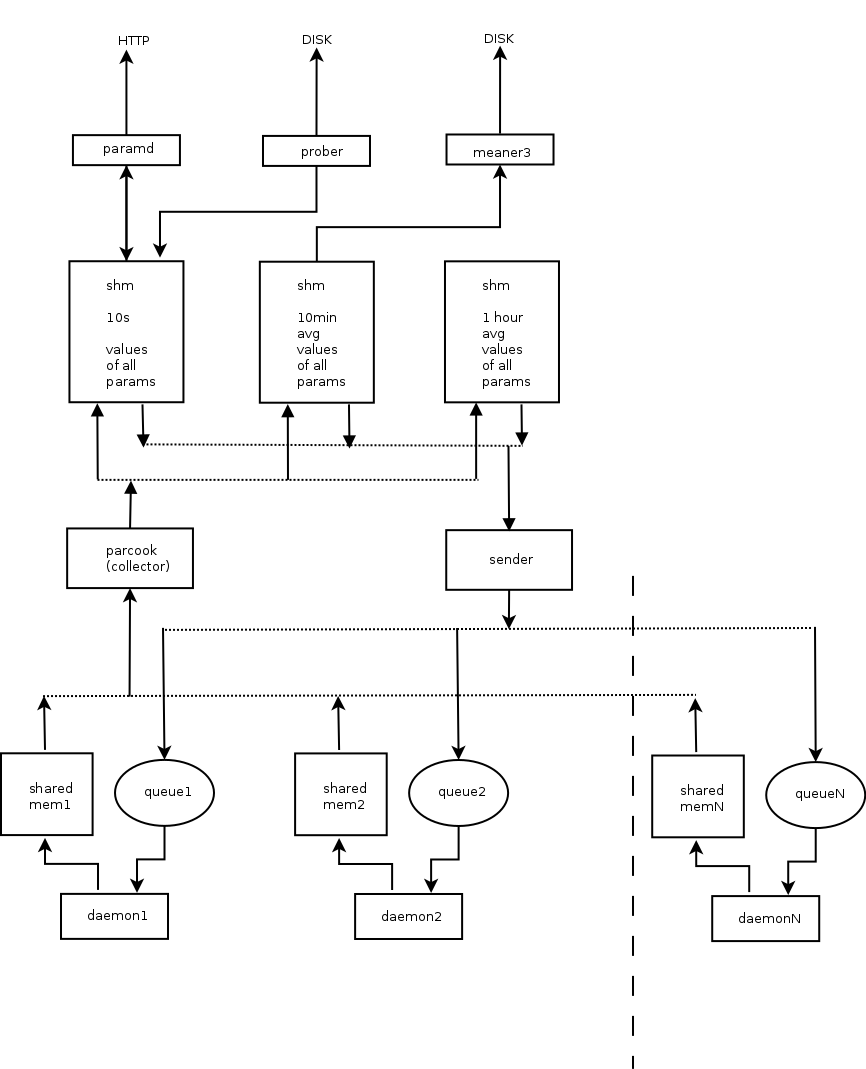
Such design and the way it is presently implemented in SZARP comes with several very nice features, like decoupling and non-fragility to failure of individual processes.
However, there are also some drawbacks to the implementation, which with time become irritating enough, that the need for changes become apparent.
One of the limitations of current approach is that the data in the collection/propagation pipeline (the thing depicted above) have no timestamps associated. Everything sitting in there is considered to be a live value. Data in the shared memory regions is accessed periodically by respective components at fixed time intervals. The exact moment when it happens is determined by each process individual clock (modulo the locking constraints), and those clocks are not synchronized. So, while storing a value to the database we cannot be exactly sure when this value comes from – only that it was acquired sometime in between 1 to 4 clock ticks ago. Which in most of the cases is just fine, as the clocks are ticking fast enough, for this to not matter. But sometime it would be nice to be more precise and also faster.
Another annoyance is that the data collection pipeline works basically with only one data type (and pretty limited at that) which 16 bit integer. In fact that’s exactly what shared memory regions are holding – raw arrays of short integers. Due to certain hacks introduced here and there, this is not exactly correct and SZARP is equally fine with collecting data of larger size, but the truth is the problem of acquiring values of different types and sizes is not solved in a systematic way.
So, as the title of this post suggests, we are in the process of introducing changes that are supposed to address those 2, and some others, lesser problems. As it comes, it is pretty big change, but the good news is that we should be able to make this incrementally so the risk of breaking too many things, is relatively low.
So without further ado, ladies and gentlemen, lo and behold, the new (planned) SZARP data acquisition pipeline (artistic impression of another artist):
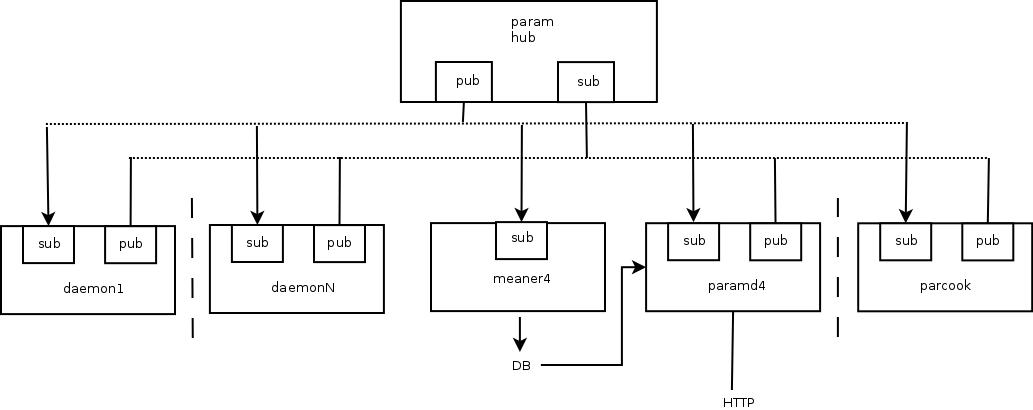
There are a few differences between new and old design. First of all, the inter-process communication primitive is no longer shared memory regions, but publisher-subscriber ZeroMQ sockets.
There is a new, main central component in the system, param hub, which is tasked with broadcasting everything it gets on sub socket onto the pub socket. That is the only part of the system that other components need to be aware of and connect to.
The other significant departure from the existing design is that all the messages exchanged between processes are timestamped, so no matter how much time the message travels along the pipeline, it is always clear when that particular datum was collected/generated. Also, those msgs are transmitted asynchronously, which means that the receiving component is not bound by any particular clock or set of clocks, and is free to act on new data as soon as they arrive.
Needless to say, we are also giving up on the assumption that everything is a short int.
And last but not least, the important feature of this architecture is that we can plug in good-old parcook as a yet another piece of the puzzle here. That means that there will be no big-bang needed and we can incrementally work our way towards new design by gradually adapting existing daemons/components.
Let’s see how it goes!