Since version 3.23.07 SZARP stable packages are available also for Debian Bookworm.
Moving to GitLab
SZARP moves its source code to GitLab! Our repository is now available at this site. Transition to new Git-repository manager happened because of many advantages relative to GitHub. Because of built-in Continuous Integration system we can deliver updates of our software quicker. Multiplicity of available tools let us focus on code writing and ensure about better quality of our product.
GitLab has got many practical functionalities, for example integrated issue tracking system which allowes us for modifying multiple tasks simultaneously. As it is widely known quality of code depends strongly on rigorous code reviews and from now we don’t need to engage external tools because GitLab offers to us built-in solution. Besides that it has got code production monitoring mechanism and ability to manage project by using SSH. Big advantage of GitLab is also detailed documentation concerning repository operations. Next functionality from which we benefit from is ability to run this manager on our server with no worries about security and availability issues of third party companies 😉 Also growing number of programmers that GitLab unites encouraged us to change Git-repository managing platform.
We also unified our licensing to GPLv3. The most important changes in it were in relation to software patents, free software license compatibility, the definition of “source code”, and hardware restrictions on software modification (“tivoization”). More info at GNU project website.
Next novelty concerns about SZARP under Windows! We replaced maintenance of separate code for Microsoft’s operating system users by new functionality that appeared on Windows 10 Professional. Users of that system can use latest version of our software by using Ubuntu Shell (here is how to do it). Thanks to that functionality Windows users can now use Linux version of SZARP, and we, programmers, can focus on developing one code which significantly simplifies its maintanance.
Developing of SZARP continues
Recently, a lot has happened in our github project. We started with a general code review to get rid of all sorts of bugs and warnings at compile and build packages with our SZARP. On the occasion of this work we abandoned support for Analysis (boilers are out!), Psetd, and a large range of extinct daemons. Then we moved our window applications to a more up-to-date version of wxWidgets which will greatly streamline the introduction of new functionality. In the meantime, we’ve improved the heap (not stack) of bugs, very often mistakenly labeled as features. This year, the team of contributors came out with a shield. Even three.
During this work, the need for a new Danfoss FC protocol was born. This protocol specifies the master-slave access technique for serial communication. We will not dwell on specifics here, but it is worth mentioning the quality and amount of documentation. Just be careful – the English version of the documentation is the only recommendable.
After a brief discussion on whether it should be a separate program or whether it can use all the good offered by metadaemon, more commonly known as borutadmn, the answer was clear. Our good borough will get another protocol to handle. Where to start?
We started by reviewing the documentation (once again we recommend English version!), wherein we define the critical moments of this protocol. We promised not to get into the detailed specifications, but the protocol required that. From the documentation we learned that in order to obtain data we have to create a 16 byte telegram

- STX is always 0x02 (we do not like magic numbers),
- LGE in case of 16 byte telegram will always be 0x0E (hic!) ¹,
- This ADR is the address of our slave, enlarged by 0x80 (the 7th bit is always 1),
- Databytes are the contents of a telegram (described below),
- BCC is a logical sum of XOR logic on all remaining bytes
Databytes in our case contains 6 of 2 bytes positions – PKE, IND, PWEHIGH, PWELOW, PCD1, PCD2. There is a parameter number in the PKE and a function that the inverter is requested to do with the parameter. IND is used to query array parameters. Other items are used by the slave to provide information.
Backing to borutadmn, it is a metadaemon that already has plugins for supporting protocols such as modbus (tcp and serial, client and server), zet (tcp and serial, client), fp210 (serial, client), lumel (serial, client) wmtp (tcp, client). It is based on libevent event handling, which ensures continuity of tasks on many devices. This ensures efficient work with minimal hardware effort. By writing a new module for our metadata we tried to keep the C ++ 11 standard, which was not always in line with the spirit of our boruta.
After a few days of uneven battle, the borutadmn was abducted and our contributor received the first data from the Danfoss VLT 6000 inverter. There was a so-called test phase on the table that detected a plenty of abnormalities in maintaining communication stability. These errors were quickly localized and corrected.
Configuration of the Danfoss inverters using the FC protocol is very similar to the daemon configuration for other protocols. For our new module we had to introduce a new attribute to param, called parameter-number, located in the ipk-extra namespace. It corresponds to the parameter number we want to read. For configuration details, please visit our Documentation section.
In the near future, the plugin should appear in the newer metadata borutadmn_z based on libzmq, which offers even more possibilities, including read and write 2/4 byte unsigned data.
__________________
¹ – for our needs we only use 16 byte telegrams (LGE = 0x0E), but 8 byte telegrams are allowed – then LGE = 0x06
New szarp repository address
From now szarp.org website will be served via https protocol, due to new good practicie standards considering world wide web. At the same time we’re changing szarp repository access method. From this day on szarp repository is located under packages.szarp.org. For further instructions please visit download section.
Evolving SZARP architecture!
SZARP, since the very beginning (if we exclude short period of SZARP infancy, when it was running on multiple computers under DOS operating system) possesses architecture which is very UNIXy in its spirit. SZARP basically is a collection of processes/applications, where each of the processes is tasked with performing (mostly) one job – and (obviously) performing it well :).
In typical SZARP deployment we have one process that collects values of all parameters, another process that grabs those values and shovels them off into persistent storage, bunch of processes, so called demons, that (typically) communicate with physical devices (usually one process per device), yet another process that make parameters’ values available over HTTP protocol and so on…
All those processes employ the old school UNIX IPC (SYS V) mechanisms to communicate. The parameters’ values are stored in shared memory regions that are accessed using readers-writers locking scheme. Data sent to devices is being passed via queues (again – SYS V IPC primitive).
Here’s an artist’s impression of some of the components comprising SZARP system and the way they are interconnected:
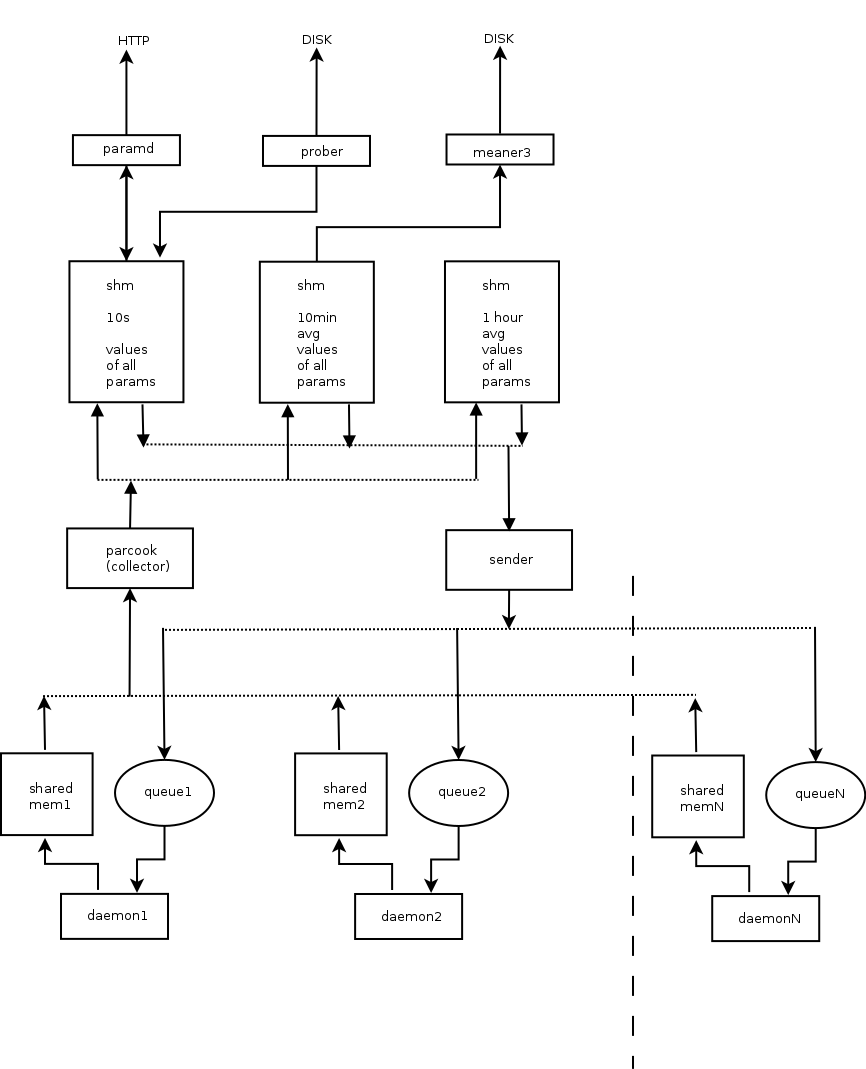
Such design and the way it is presently implemented in SZARP comes with several very nice features, like decoupling and non-fragility to failure of individual processes.
However, there are also some drawbacks to the implementation, which with time become irritating enough, that the need for changes become apparent.
One of the limitations of current approach is that the data in the collection/propagation pipeline (the thing depicted above) have no timestamps associated. Everything sitting in there is considered to be a live value. Data in the shared memory regions is accessed periodically by respective components at fixed time intervals. The exact moment when it happens is determined by each process individual clock (modulo the locking constraints), and those clocks are not synchronized. So, while storing a value to the database we cannot be exactly sure when this value comes from – only that it was acquired sometime in between 1 to 4 clock ticks ago. Which in most of the cases is just fine, as the clocks are ticking fast enough, for this to not matter. But sometime it would be nice to be more precise and also faster.
Another annoyance is that the data collection pipeline works basically with only one data type (and pretty limited at that) which 16 bit integer. In fact that’s exactly what shared memory regions are holding – raw arrays of short integers. Due to certain hacks introduced here and there, this is not exactly correct and SZARP is equally fine with collecting data of larger size, but the truth is the problem of acquiring values of different types and sizes is not solved in a systematic way.
So, as the title of this post suggests, we are in the process of introducing changes that are supposed to address those 2, and some others, lesser problems. As it comes, it is pretty big change, but the good news is that we should be able to make this incrementally so the risk of breaking too many things, is relatively low.
So without further ado, ladies and gentlemen, lo and behold, the new (planned) SZARP data acquisition pipeline (artistic impression of another artist):
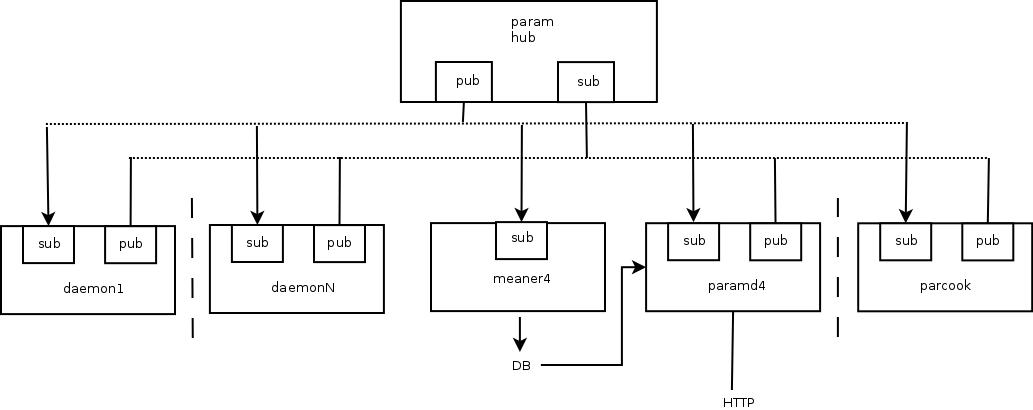
There are a few differences between new and old design. First of all, the inter-process communication primitive is no longer shared memory regions, but publisher-subscriber ZeroMQ sockets.
There is a new, main central component in the system, param hub, which is tasked with broadcasting everything it gets on sub socket onto the pub socket. That is the only part of the system that other components need to be aware of and connect to.
The other significant departure from the existing design is that all the messages exchanged between processes are timestamped, so no matter how much time the message travels along the pipeline, it is always clear when that particular datum was collected/generated. Also, those msgs are transmitted asynchronously, which means that the receiving component is not bound by any particular clock or set of clocks, and is free to act on new data as soon as they arrive.
Needless to say, we are also giving up on the assumption that everything is a short int.
And last but not least, the important feature of this architecture is that we can plug in good-old parcook as a yet another piece of the puzzle here. That means that there will be no big-bang needed and we can incrementally work our way towards new design by gradually adapting existing daemons/components.
Let’s see how it goes!
Character encoding cleanup in SZARP
In the past half-year we did some profound cleanup in character encoding in SZARP. Many users may consider this as negligible, but in fact it could be a bit of hassle – especially for Polish users. What’s the point? SZARP software has been developed continuously for over 20 years, so for sure one will find in it parts of code written a dozen or so years ago. In that time character encoding were not as straight forward as it is today. A series of standards, gathered in ISO/IEC 8859, were commonly used. Year 2006 brought a change – a character encoding UTF-8 (which implements Unicode standard) started gaining popularity and in a few years it has become the dominant for the World Wide Web. Again, what’s the point? SZARP is using UTF-8 for some time.
Well, not exactly. It appeared that in many parts of code Latin-2 (ISO/IEC 8859-2) were still considered as default or even hard-coded! (it seemed appropriate 10 years ago) It also applied to SZARP’s encoding conversion module and that’s why it bit from time to time. The issue had to be put straight.
Introduced changes did not take a lot of code-lines (not more than a few hundreds), but possibly may affect almost every part of SZARP. For that reason they had been carefully tested. Nevertheless a few bugs spilled out month or two later.
Today, after a half year of our effort and decent testing, we announce that SZARP is fully capable of UTF-8 character encoding standard.
SZARP for mobile devices
From now on SZARP supports mobile devices. The mobile version of SZARP Draw offers all the basic functionality: viewing graphs, split cursor mode, mean and summaric values, finding parameters and sets by name. We chose HTML5+JS as the core technology to ensure that the application would run on all mobile devices, on every OS (in particular, Android and Windows Phone are supported). The user interface has been redesigned to provide comfortable navigation even on small smartphone screens, using touch events. The mobile version of the SZARP system complements the base SZARP system, which remains the core system, offering the widest range of functionality.
The application was implemented using WebSockets, offering the new web applications paradigm – asynchronous browser-server communication, where the server may update the browser state at any time. Thanks to WebSockets, new parameter values are transmitted from the server and immediately displayed on all connected client apps. Besides SZARP Draw, another example of such application is the control panel application created by Newterm (screenshots below).
The taste of things to come…
We’ve been severly neglecting readers of szarp.org over last serveral months and we’re very sorry about that. To compensate for this, we decided to give you, our beloved readers, a little visual seak peek at what we’ve been up to recently.
So, lo and behold – draw3 and sz4 engine in action!
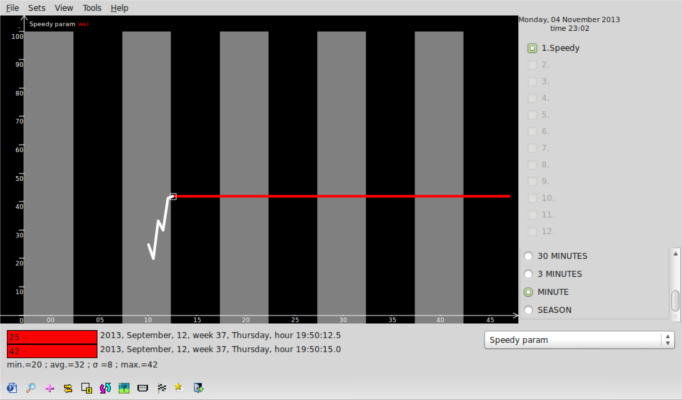
What you can see on the picture is good ol’ draw3 hooked to brand new, almost completed sz4 database engine. What’s all the fuss about, you may ask, after all it’s just draw3 drawing some graph. And yes, this is indeed true. However if you take a closer look you may notice one novel thing – the time resolution of the graph being displayed. New database engine is able to store data with subsecond time resolution and now draw3 is capable of (at least partially for now) taking adantage of this fact.
Theoretically new database format lets us store data with up to 1ns precision, however other factors are limiting this value somewhat – e.g. draw3 due to usage of wxWidgtes date and time classes is only able to draw trends with up to 1 ms resolution, but if the need arises we could go definitely go lower than that.
So, when it’s going to be production ready – I hear you asking. Soon, we hope. There are still some bits and pieces missing and we’re also have some bugs to squash. So, stay tuned!
SZARP on Ubuntu Precise
Upon popular demand (with a little delay though) we officaly start to support SZARP on Ubuntu 12.04 LTS (Precise Pangolin).
As usual, in order to install SZARP on Ubuntu precise point your favourite package manager to:
deb http://newterm.pl/debian precise main
SZARP moves to github
Following latest trends, SZARP project is moving its source code repository to github.
The new project’s URL is https://github.com/Newterm/szarp. In order to fetch SZARP’s source code use command:
git clone https://github.com/Newterm/szarp.git
We’ll keep our sourceforge repository for some time, however we do not plan to commit any new stuff in there.
Alive and kickin’
Hello.
We’ve been little sluggish on updating you with news from SZARP world for a last few months. It’s not because nothing of interest was happening with our system. Quite the contrary – we’ve been doing some serious groundwork on core SZARP components. It’s just that updating szarp.org occupies low position on our priority list, there are always things to do that are more important or fun ;).
But now that moment has finally come – on a gentle nudge from the guy who is paying our salaries, we had no choice but to give you some update on what is going on with SZARP 😉
In my opinion the most important, but not yet complete, is change of a database format. The goal is to let SZARP store data with (nearly) arbitrary time resolution, effectively. In addition to the extra flexibility, this also brings other advantages over existing format:
- database occupies less disk space
- (as a consequence of previous point) database sync takes less time
- there is no longer distinction between high-resolution probes that sit on a server and can only be accessed trough TCP connection and archival data of 10 minute resolution that can be synchronized to local machine, with new db format all data can be synchronized to local machine and viewed with no connection to a server.
While working on new database format, we make our new db engine to support multiple data types (our old db supports just one data type). This is also a change that will make our life easier, but for SZARP to be able to take advantage of that improvement, other components of the system will need to be adapted. Even more goodies will be coming with new db format/engine but we’ll talk about them more once we have the code ready.
Of course this is not the only thing that we have been busy with. Here follows the list of changes that are not as major as the db switch, but still are worth highlighting:
- draw3 has a data extraction feature, this feature somewhat duplicates ekstraktor3 features, but with draw3 you can extract data from user defined/network parameters, which cannot be done with ekstraktor3
- szarp logging library “liblog” has been reworked to support multiple, configurable at runtime, backends, for now there exits 3 backends:
- classic – old-style (i.e. used by SZARP so far) backend directly writing to files
- syslog – backend using syslog library
- async_syslog – our home-brew, libevent based implementation of syslog protool, aimed for apps using libevent
- New feature for draw3. Some background info – on main draw3 graph widget each point (for periods decade, year, month, week and season) representes average value of parameter from corresponding time span (e.g. for period year, each point represented average param value for a month). For some types of params (especially counters) it isn’t necessarily the most interesting piece of information user would like to have. Because of this draw3 has been extended to allow user to choose among 3 different kind of values to be displayed for decade, year, month, week and season period:
- average, default and only option available so far, each point represents param average value
- last, last 10-minute probe for a point time span is drawn
- diff, difference between value of last 10-minute probe and first 10-minute of time span covered by point is drawn
New option is accessible from context menu of graphs’ list
widget. - and as usual, tons of minor changes and improvements