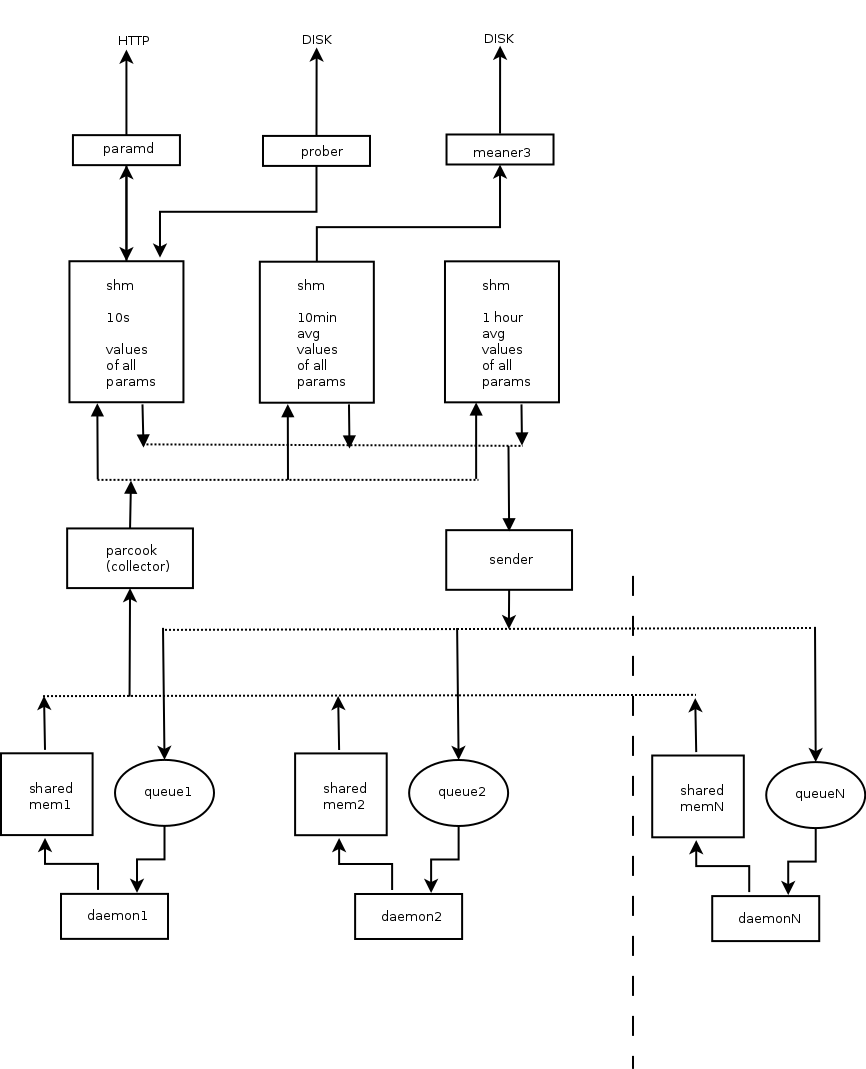
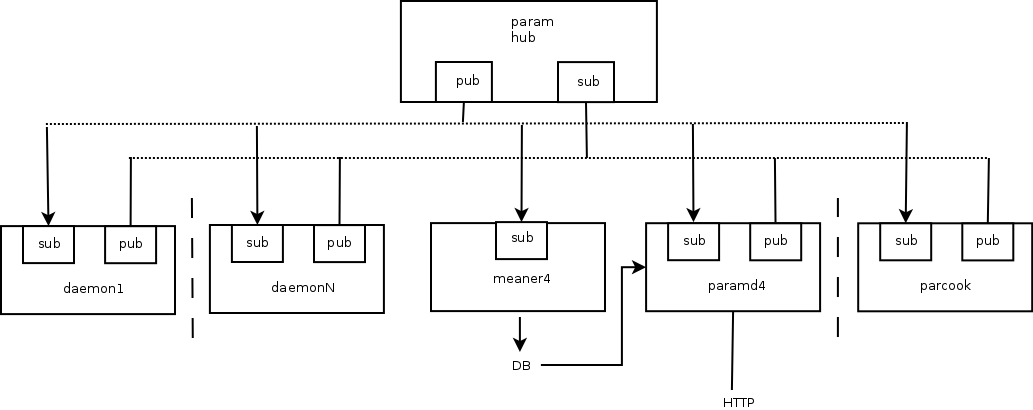
SZARP przenosi swój kod źródłowy na GitLab’a! Nasze repozytorium istnieje teraz pod tym adresem. Przejście na nową platformę do zarządzania repozytorium podyktowane zostało przez wiele jej zalet w stosunku do serwisu GitHub. Dzięki systemowi płynnego wdrażania możemy szybciej dostarczać aktualizacje naszego oprogramowania, a mnogość dostępnych narzędzi pozwala nam skupić się na pisaniu kodu i zapewnieniu najlepszej jakości naszego produktu.
GitLab posiada wiele praktycznych funkcjonalności, między innymi zintegrowany system śledzenia zadań, który pozwala na modyfikację wielu zadań jednocześnie. Jak wiadomo jakość kodu zależy w dużej mierze od rygorystycznego podejścia do jego recenzowania, a od teraz nie musimy angażować do tego zewnętrznych narzędzi, ponieważ GitLab oferuje nam wbudowane rozwiązanie. Oprócz tego posiada mechanizm monitorowania całego cyklu produkcji kodu, a także alternatywną opcję zarządzania projektem za pomocą SSH. Dużym plusem GitLab’a jest również szczegółowa dokumentacja dotycząca operacji na repozytoriach, którą udostepnia. Kolejną funkcjonalnością, z której skorzystaliśmy jest uruchomienie platformy na swoim serwerze, bez obawy o bezpieczeństwo i dostępność kodu zapewniane przez zewnętrzną firmę 😉 Oprócz ułatwień, do takiej zmiany skłoniła nas rosnąca liczba programistów, którą zrzesza GitLab.
Ujednoliciliśmy także nasze licencjonowanie do GPLv3 co ma na celu głównie dostosowanie ochrony licencyjnej do współczesnego stanu informatyki. GPLv3 bierze pod uwagę między innymi systemy prawne spoza USA, kwestie patentów na oprogramowanie, ochronę DRM, proceder tiwoizacji oraz problem istnienia wielu niezgodnych ze sobą licencji. Po więcej informacji odsyłamy na oficjalną stronę projektu GNU.
Kolejna nowinka dotyczy SZARPa pod Windows’em! Utrzymanie oddzielnego kodu dla użytkowników Microsoftowego systemu operacyjnego zastąpiliśmy nową funkcjonalnością, która pojawiła sie w systemach Windows 10 Professional. Użytkownicy tego systemu mogą korzystać z najnowszej wersji naszego oprogramowania za pomocą terminala Ubuntu (instrukcja jak to zrobić jest już tutaj). Dzięki temu użytkownicy Windowsa mają możliwość używania wersji Linuksowej, a my, programiści, możemy skupić się na rozwijaniu jednego kodu co znacznie upraszcza jego utrzymanie.